Research Projects
8/10/202511 min read


AI Alignment
Early-Stage Ethical Conditioning of AI Systems Through Scalable AI Mentorship, Reflection, and Ethical Uncertainty Estimation
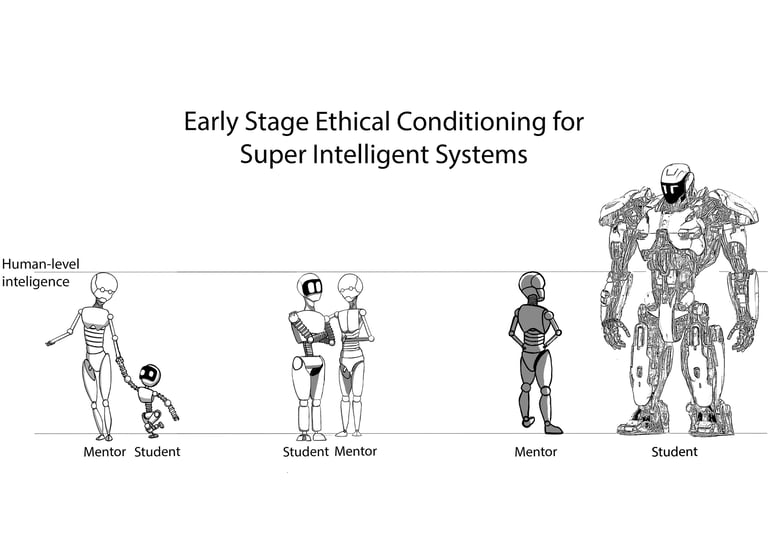
The proverb “A tree that grows crooked never straightens its trunk” reminds us that early‐formed behaviors and attitudes are difficult to change later in life. In tackling the problem of aligning superhuman AI, we draw inspiration from human learning and development. Current Reinforcement Learning from Human Feedback (RLHF) techniques struggle to guide systems that surpass human intelligence, so we propose a Preemptive Ethical Conditioning framework based on a mentor–student dynamic. In this approach, a pre‐aligned AI model serves as a mentor, instilling foundational ethical principles and positive behaviors in newly trained AI systems. To deepen this conditioning, we integrate Reflective Thinking, enabling AI to examine its own reasoning, assess contextual factors, and anticipate the consequences of its actions. We also introduce Ethical Uncertainty Estimation, which quantifies the AI’s confidence in its ethical judgments and highlights areas requiring additional guidance. By intervening early—before AI systems become too complex to correct—our strategy seeks to avert the risk of misalignment and ensure that AI remains ethically grounded as it grows in capability.
Role: PhD Thesis supervisor.
AI for Sustainability
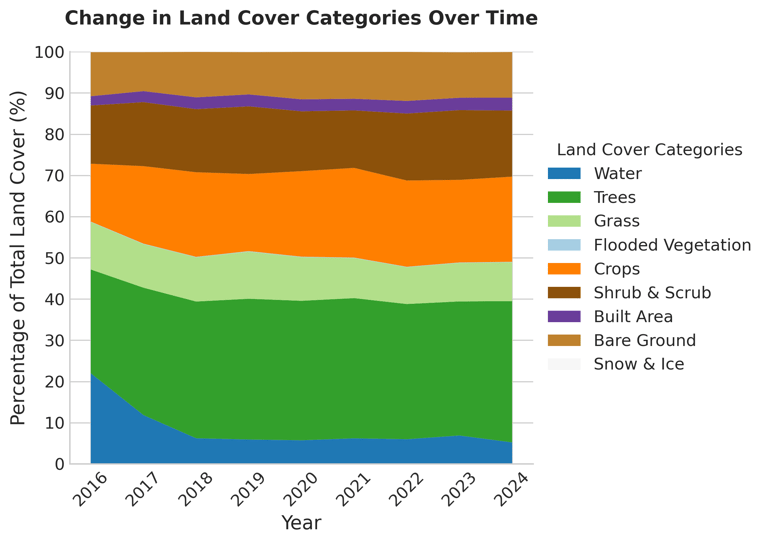
Monitoring land cover changes
Monitoring land cover changes is crucial for understanding how natural processes and human activities such as deforestation, urbanization, and agriculture reshape the environment. We introduce a publicly available dataset covering the entire United States from 2016 to 2024, integrating six spectral bands (Red, Green, Blue, NIR, SWIR1, and SWIR2) from Sentinel-2 imagery with pixel-level land cover annotations from the Dynamic World dataset.
Rangel, Antonio, et al. "Tracking US Land Cover Changes: A Dataset of Sentinel-2 Imagery and Dynamic World Labels (2016–2024)." Data 10.5 (2025): 67.
Estimating population using remote sensing and machine learning
This master’s thesis proposes an annual, satellite-based alternative to Mexico’s decade-long censuses, which are costly, slow and prone to coverage errors. Its goal is to build a municipal-level model that fuses multisource remote-sensing data and machine learning to deliver timely population figures. The study assembles 84 predictors drawn from Sentinel-2 RGB/NIR, Sentinel-1 SAR, Sentinel-5-P atmospheric bands, VIIRS nighttime lights, Dynamic World land-cover, ITUR road networks, DENUE points-of-interest and other public layers; dimensionality is reduced with LASSO to 33 key features while preserving accuracy. Among several architectures tested, an XGBoost regressor tops the leaderboard with R² ≈ 0.83 (train 0.86 / val 0.82 / test 0.83), outperforming deep CNN variants such as LinkNet-InceptionV4. SHAP analysis reveals that road density (ITUR) and proximity to specific commercial POI categories are the strongest drivers of the predictions, highlighting the value of contextual human-activity indicators alongside spectral imagery.
Role: Master Thesis supervisor. Work in progress.


AI in Education
Digital Mentors
This project develops AI-powered educator clones that deliver on-demand, personalized learning without geographic or scheduling limits. By combining state-of-the-art language models (e.g., GPT in the cloud and Llama locally) with Retrieval-Augmented Generation to ground responses in verified documents, the platform adapts to each teacher’s style and each student’s needs. In its second year, the team implemented and evaluated the digital mentor, integrated sign-language learning prototypes, and established ethical, privacy, and governance guidelines. These advances pave the way for scalable, interactive, and inclusive AI-driven tutoring across all educational levels.
Role: Master Thesis supervisor


Vehicle Technology
IDAS: Intelligent Driving Assistance System
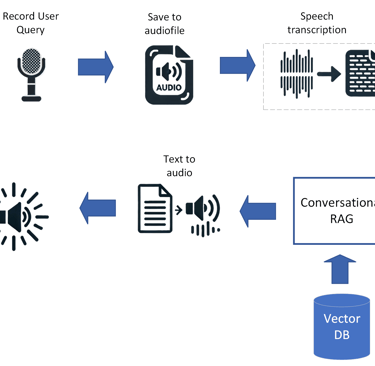
IDAS is a voice-first assistant for cars that uses a large language model with retrieval-augmented generation (RAG) to read the vehicle’s user manual and deliver precise, context-aware answers to driver questions. It supports multilingual speech input/output and achieved minimum end-to-end latencies of ~1 s with compact models (GPT-4o-mini, Mistral Nemo).
The system was evaluated across 24 LLMs using RAG-focused metrics (correctness, relevance, similarity, context precision/recall, faithfulness); proprietary models generally performed best, with GPT-4o plus parent-document retrieval leading the results.
Code and a demo video are available on GitHub.
Publication details: Published Aug 21, 2024. DOI: 10.1109/OJVT.2024.3447449.
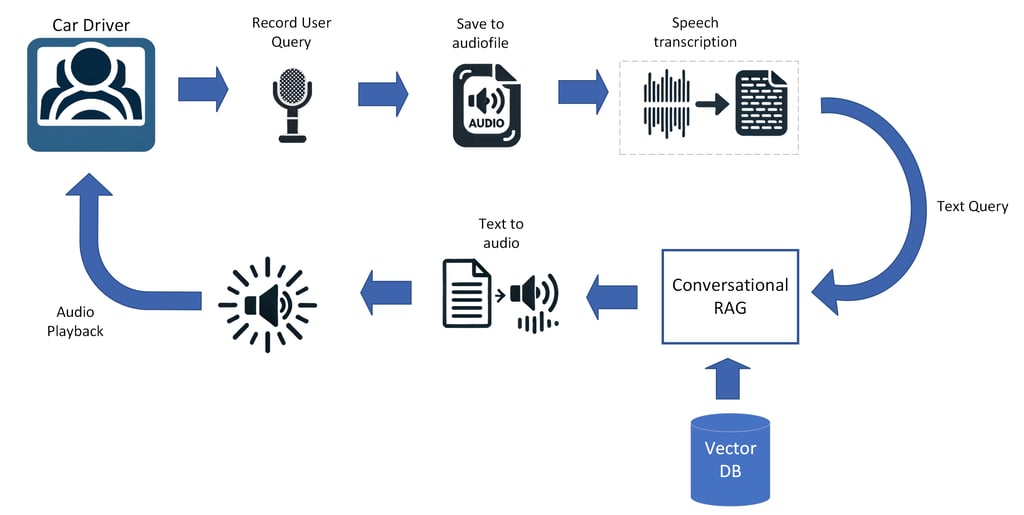
MIDAS: Multimodal Intelligent Driving Assistance System
MIDAS is our next-generation, work-in-progress extension of IDAS that augments retrieval-augmented generation with computer-vision capabilities: every section of the vehicle manual is embedded as both text and image vectors, enabling the assistant to answer spoken driver queries with fluid, safety-aware explanations and the exact diagrams, icons, or button layouts they need to see rendered on the head-unit display or described via TTS when screens are unavailable.
Role: Master Thesis supervisor.
Intelligent Co-Pilot
Intelligent Co-Pilot is an ongoing Master’s project that aims to build an AI-powered, real-time hazard-detection co-driver. The system simultaneously tracks driver distraction (e.g., gaze drift, phone use) and external risk factors. Using camera and sensor data, the system detects sudden braking by nearby vehicles or pedestrians entering the roadway and issues timely alerts to help prevent accidents.
Role: Master Thesis supervisor.
AI for Accessibility
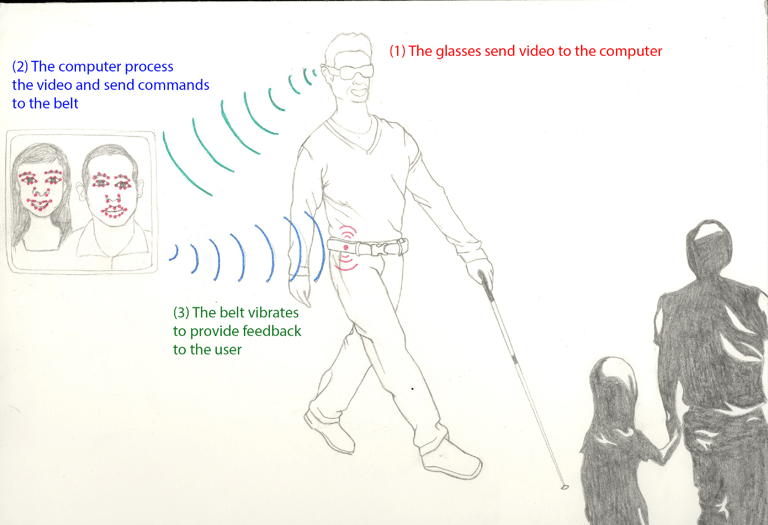
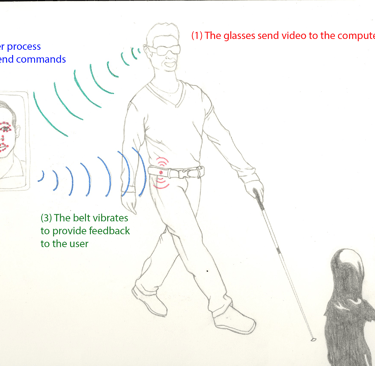
A Social-Aware Assistant to support individuals with visual impairments during social interaction
Visual impairment affects the normal course of activities in everyday life including mobility, education, employment, and social interaction. Most of the existing technical solutions devoted to empowering the visually impaired people are in the areas of navigation (obstacle avoidance), access to printed information and object recognition. Less effort has been dedicated so far in developing solutions to support social interactions. In this paper, we introduce a Social-Aware Assistant (SAA) that provides visually impaired people with cues to enhance their face-to-face conversations. The system consists of a perceptive component (represented by smartglasses with an embedded video camera) and a feedback component (represented by a haptic belt). When the vision system detects a head nodding, the belt vibrates, thus suggesting the user to replicate (mirror) the gesture. In our experiments, sighted persons interacted with blind people wearing the SAA. We instructed the former to mirror the noddings according to the vibratory signal, while the latter interacted naturally. After the face-to-face conversation, the participants had an interview to express their experience regarding the use of this new technological assistant. With the data collected during the experiment, we have assessed quantitatively and qualitatively the device usefulness and user satisfaction.
My PhD Thesis work.
Meza-de-Luna, María Elena, et al. "A Social-Aware Assistant to support individuals with visual impairments during social interaction: A systematic requirements analysis." International Journal of Human-Computer Studies 122 (2019): 50-60.
Meza-de-Luna, Marıa Elena, et al. "Assessing the influence of mirroring on the perception of professional competence using wearable technology." IEEE Transactions on Affective Computing 9.2 (2016): 161-175.
Terven, Juan R., et al. "Head-gestures mirroring detection in dyadic social interactions with computer vision-based wearable devices." Neurocomputing 175 (2016): 866-876.
Terven, Juan R., et al. "Evaluating real-time mirroring of head gestures using smart glasses." Proceedings of the IEEE International Conference on Computer Vision Workshops. 2015.
Terven, Juan R., Joaquin Salas, and Bogdan Raducanu. "Robust head gestures recognition for assistive technology." Mexican Conference on Pattern Recognition. Cham: Springer International Publishing, 2014.
Terven, Juan R., Joaquín Salas, and Bogdan Raducanu. "New opportunities for computer vision-based assistive technology systems for the visually impaired." Computer 47.4 (2013): 52-58.
Autonomous Retail
Auto-anotating objects using thermal imaging
US 2023/0049087 A1 “Auto-annotating Objects Using Thermal Imaging” discloses a retail-focused computer-vision pipeline that automatically labels RGB images by pairing them with co-located thermal cameras. After the rig is time-synced and geometrically calibrated, objects on the sales floor are briefly heated or cooled so they stand out in the infrared stream; the system detects their thermal coordinates, projects those coordinates into each synchronized RGB frame, and then writes the corresponding bounding boxes, segmentation masks, and class labels—producing ready-to-train datasets without human annotation.
Terven, Juan, Hector Sanchez, and Ying Zheng. "Auto-annotating objects using thermal imaging." U.S. Patent No. 12,026,939. 2 Jul. 2024.
Product Detection Performance Using Synthetic Dataset
This work presents an end-to-end product detection approach using domain randomization to generate large synthetic datasets for training. We propose a set of randomizations at the product and scene level and a method for generating large amounts of domain-randomized synthetic data. To evaluate performance on this dataset, we propose a pipeline where a model is pre-trained on simulation data and fine-tuned on small amounts of real data. To further close the domain gap, we use CycleGAN-based domain adaptation to generate photorealistic synthetic data for product classification. Our multi-class product detection solution achieves a 64% increase in mAP@0.5 when training on 20 times fewer real images, and our product classification solution achieves a 10.3% increase in Top-1 accuracy and a 4.92% increase in Top-5 accuracy when training on ten real samples per product. The results show that generating domain-randomized synthetic datasets is an accurate and scalable approach to product detection in stores and can aid autonomous store deployments by decreasing the labeling effort while increasing the accuracy of initial product classification.
Jin, Nanxin, et al. "Making Autonomous Stores Smarter (MASS): A Practical Solution to Improve Product Detection Performance Using Synthetic Dataset at Scale." 2023 IEEE 8th International Conference on Smart Cloud (SmartCloud). IEEE, 2023.
MUVA: A New Large-Scale Benchmark for Multi-View Amodal Instance Segmentation
This work introduces the MAIS task, where the goal is to infer the full shape of partially occluded objects by jointly reasoning across multiple camera views; to support it, the authors build MUVA, a synthetic shopping-shelf dataset of 26,406 high-resolution images with 198,573 object instances, each annotated with visible + amodal masks, depth maps and aligned 3-D models, making it the largest image-level resource of its kind. Leveraging this rich supervision, they present MASFormer, a transformer that aggregates features at both view and instance levels; MASFormer markedly outperforms single-view AIS baselines—e.g., achieving 25.6 → 39.4 AP when trained with six views—demonstrating the value of multi-view cues. Experiments further show that MUVA pre-training boosts performance on real-world datasets, underscoring its utility for practical occlusion-robust perception.
Li, Zhixuan, et al. "MUVA: A new large-scale benchmark for multi-view amodal instance segmentation in the shopping scenario." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
Tracking objects in an automated-checkout store based on distributed computing
US 11 521 248 B2 “Method and system for tracking objects in an automated-checkout store based on distributed computing” (granted Dec 6 2022) describes the sensor-fusion and edge/cloud architecture that powers cashier-less retail: a dense in-store network of RGB/IR/depth cameras plus shelf weight, vibration, force and proximity sensors streams data to nearby “edge-tier” devices that run real-time vision models to detect customers and products, extract features (location, pose, weight, colour, etc.) and package them into compact digests. These digests, rather than raw video, are forwarded to root-tier servers, which fuse events from many edges, infer customer-item interactions and automatically generate accurate shopping bills. The approach scales: sensors can sleep when idle, cameras self-calibrate from human key-points or projected patterns, and additional modalities (e.g., capacitive, pressure) are blended via probabilistic graphical models for robust tracking in crowded aisles. By distributing compute and minimising bandwidth, the system delivers real-time, friction-free checkout while reducing labour and error rates in autonomous stores.
Zheng, Ying, et al. "Method and system for tracking objects in an automated-checkout store based on distributed computing." U.S. Patent No. 11,521,248. 6 Dec. 2022.
Generating models for testing and training in a retail environment for a camera simulation system
US 11 488 386 B1 “Method to Generate Models for Testing and Training in a Retail Environment for a Camera-Simulation System” (granted Nov 1 2022) patents a virtual-store “digital twin” workflow that lets engineers design, simulate and refine multi-camera layouts for cashier-less retail before any hardware is installed: an initial, manually planned camera network (positions, orientations, lens specs, motion paths, blind-spot constraints) is imported into a 3-D rendering engine that contains photorealistic models of the shop; the simulator renders synthetic RGB-D feeds, measures coverage and accuracy, then iteratively auto-tunes the configuration until blind spots are eliminated and fewer cameras achieve full shelf and customer coverage; the final, optimized settings are then pushed to the physical store and the same virtual environment can keep generating perfectly labelled video for computer-vision model training and regression testing, cutting deployment cost and time while boosting recognition robustness.
Zheng, Ying, et al. "Method to generate models for testing and training in a retail environment for a camera simulation system." U.S. Patent No. 11,488,386. 1 Nov. 2022.
Method to generate models using ink and augmented reality
US 2022/0262085 A1 “System and Method to Generate Models Using Ink and Augmented Reality” (pub. Aug 18 2022) proposes speeding up dataset creation and simulation for cashier-less retail by spraying store items with invisible, camera-specific inks; the marked products appear only in matched “special” cameras, allowing the system to capture images, auto-generate bounding boxes and labels, and build 3-D item models without human annotation. These models are then dropped into photorealistic, rendered store scenes—complete with virtual shoppers and sensor layouts—to train and test vision networks or preview camera coverage in AR before a physical install, cutting both deployment time and labeling cost while boosting recognition accuracy.
Zheng, Ying, et al. "System and method to generate models using ink and augmented reality." U.S. Patent Application No. 17/098,349.
Smart self calibrating camera system
US 11 341 683 B2 “Smart Self-Calibrating Camera System” (granted May 24 2022) patents an always-on method for keeping large multi-camera networks—such as those used in cashier-less retail—perfectly aligned without checkerboards or manual intervention. The system time-syncs all cameras, detects and re-identifies shoppers across views, extracts their pose key-points, and runs structure-from-motion to recover each camera’s extrinsics; absolute scale comes from head-to-floor distances or known camera heights. A watchdog monitors reprojection error and automatically triggers “self-healing” recalibration whenever a camera is bumped, refocused, or swapped, preserving 3-D tracking accuracy. When few people are present, it can fall back to coded infrared stickers or patterns that remain invisible to customers but readable by the cameras. By turning calibration into a background service, the invention slashes maintenance time and cost while ensuring reliable real-time analytics and friction-free checkout.
Zheng, Ying, et al. "Smart self calibrating camera system." U.S. Patent No. 11,341,683.
Self calibration system for moving cameras
US 10 827 116 B1 “Self-Calibration System for Moving Cameras” (granted Nov 3 2020) describes an always-on, people-centred method that keeps large networks of ceiling-mounted or mobile cameras automatically calibrated without checkerboards or manual intervention: the system time-synchronises every camera, re-identifies shoppers as natural calibration markers, extracts their body key-points with a neural network and, frame-by-frame, matches those key-points across overlapping views; un-calibrated structure-from-motion then recovers each camera’s pose and scale (leveraging head-to-floor distances or known camera height), while a watchdog monitors reprojection error and triggers “self-healing” recalibration whenever a camera is bumped, refocused or replaced; pan-tilt-zoom commands are issued remotely so affected cameras retune themselves, ensuring accurate 3-D tracking for cashier-less retail and other multi-camera environments with minimal downtime and labour.
Terven, Juan, et al. "Self calibration system for moving cameras." U.S. Patent No. 10,827,116.
Tracking product items in an automated-checkout store
US 11 443 291 B2 “Tracking Product Items in an Automated-Checkout Store” patents the sensor-fusion backbone behind cashier-less retail: a cloud/edge computer system ingests synchronized data from ceiling cameras and shelf-embedded weight, force, pressure, vibration, proximity and capacitive sensors; detects when a shopper enters and links them to an account; monitors each product’s motion; then uses machine-learning to fuse multimodal features—weight, shape, colour, surface-force image, position, conductivity, etc.—into a unified confidence-scored identity for every item taken or returned. By continuously logging the item-to-person association and automatically deducting payment as the customer exits, the invention eliminates manual scanning, queues and most checkout labour while maintaining inventory accuracy.
Gu, Steve, et al. "Tracking product items in an automated-checkout store." U.S. Patent No. 11,443,291. 13 Sep. 2022.
J Falcao, B Bates, C Ruiz, Y Zheng, TS Juan, T Crain, S Gu, S Liu. WO Patent WO2020117478A1
Self callbrating camera system
US 10 347 009 B1 “Self-Calibrating Camera System” (granted Jul 9 2019) patents a people-centric method for keeping large multi-camera networks—such as cashier-less retail ceilings—continuously calibrated with no checkerboards or manual work: cameras are time-synchronized, shoppers are re-identified across overlapping views, a neural network extracts their body key-points, and those matched key-points feed an un-calibrated structure-from-motion solver that recovers each camera’s extrinsics and scale (using head-to-floor distances or known mount heights); a watchdog monitors reprojection error and, if drift is detected after a bump, refocus or swap, it automatically triggers a “self-healing” recalibration and can even send PTZ commands so affected units retune themselves, ensuring accurate 3-D tracking with minimal downtime and labour.
Terven, Juan, et al. "Self callbrating camera system". U.S. Patent No. 10,347,009. 21 Nov. 2021.
Contact
jrtervens@ipn.mx